Функция аппроксимации в excel
Функция ЛГРФПРИБЛ для аппроксимации данных таблиц в Excel
Функция ЛГРФПРИБЛ в Excel предназначена для определения значений, на основе которых может быть построена экспоненциальная кривая, аппроксимирующая имеющиеся числовые данные, и возвращает массив значений. Для корректной работы рассматриваемой функции ее следует вводить как формулу массива.
Методы аппроксимации табличных данных в Excel
Функция ЛГРФПРИБЛ возвращает данные, необходимые для построения кривой, описываемой следующим уравнением:
Если имеется две и более переменных, это уравнение переписывается следующим образом:
Возвращаемые рассматриваемой функцией данные представляют собой следующий массив:
То есть, имеем массив оснований, возводимых в степени (известные значения переменных x), и коэффициент b.
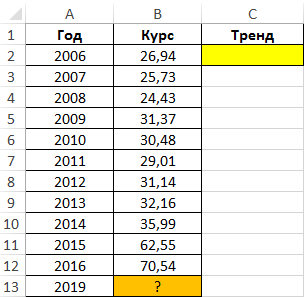
Пример 1. В таблице приведены данные, характеризующие динамику курса доллара на протяжении 10 лет (с 2006 по 2016 год). Необходимо спрогнозировать курс доллара на 2019 год на основании имеющихся данных.
Вид таблицы данных:
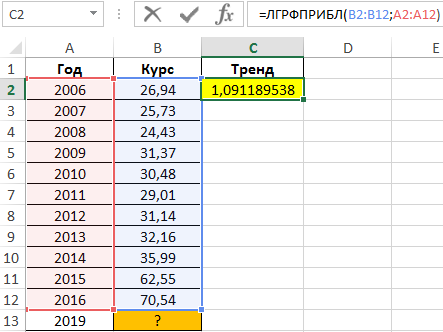
Для расчета тренда (коэффициент, используемый для предсказания последующих значений курса) используем функцию:
- B2:B12 – известные данные зависимой переменной (значения курса);
- A2:A12 – известные данные независимой переменной (года).
Для предсказания курса на 2019 год используем формулу:
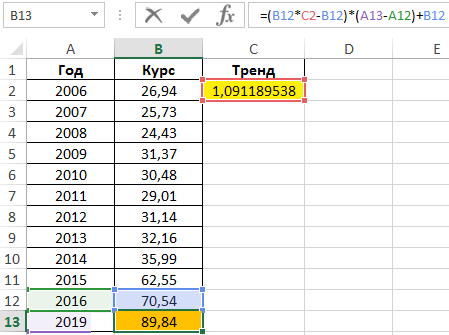
Как видно, полученное значение имеет небольшую степень достоверности. Использование данного типа аппроксимации для предсказания курса валют нерационально.
Прогнозирование финансовых результатов методом аппроксимации в Excel
Пример 2. В таблице имеются данные о зарплатах за прошедший год (помесячно). Определить оптимальный способ предсказания размеров зарплат для последующих периодов.
Вид таблицы данных:
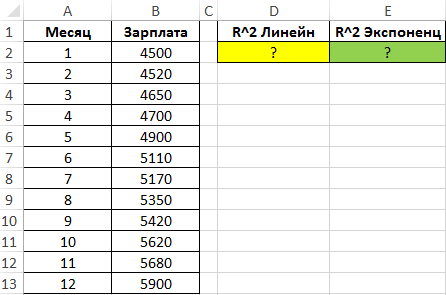
Определим коэффициенты достоверности аппроксимации для линейной и экспоненциальной функций с помощью следующих функций (вводить как формулы массива CTRL+SHIFT+Enter):
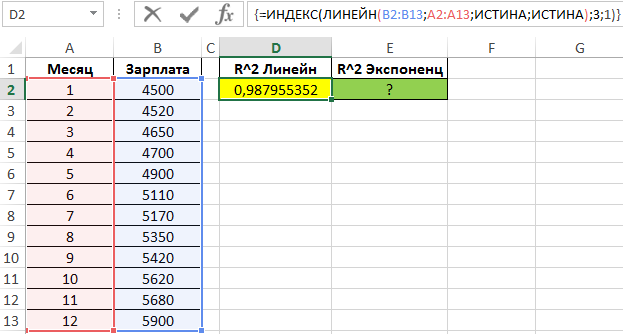
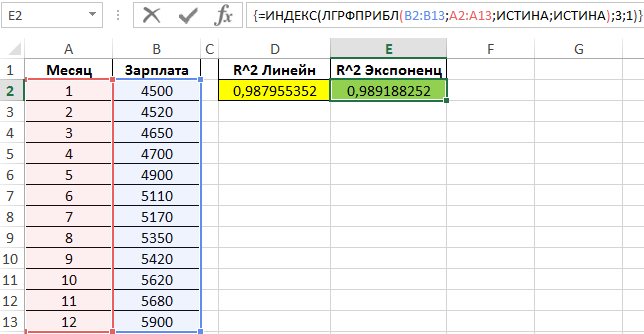
Поскольку обе функции возвращают результат в виде массива данных, в котором в третьей строке первого столбца содержится искомое значение R^2, используем функцию ИНДЕКС для возврата желаемого результата.
Чем ближе значение R^2 к 1, тем выше точность аппроксимации. Как видно, наибольшую точность обеспечивает экспоненциальная функция. Однако разница не является существенной, поэтому использование функции ЛИНЕЙН является допустимым в данном случае.
Правила метода аппроксимации по функции ЛГРФПРИБЛ в Excel
Функция имеет следующую синтаксическую запись:
=ЛГРФПРИБЛ( известные_значения_y; [известные_значения_x];[конст];[статистика])
- известные_значения_y – обязательный, принимает ссылку на диапазон ячеек или массив данных — числовые значения, которые характеризуют состояние зависимой переменной y из указанного выше уравнения;
- [известные_значения_x] – необязательный, принимает ссылку на диапазон ячеек или массив чисел, которые являются уже известными значениями независимой переменной x. Если явно не указан, по умолчанию принимается массив значений <1;2;…N>, где N – количество элементов в массиве, характеризующем известные_значения_y ;
- [конст] – необязательный, принимает данные логического типа, интерпретируемые следующим образом: ИСТИНА или явно не указан – функция вычисляет значение коэффициента b из приведенного выше уравнения, ЛОЖЬ – значение данного коэффициента принимается равным 1;
- [статистика] – необязательный, принимает логические значения ИСТИНА (функция возвращает дополнительные данные на основе проведенного регрессионного анализа) или ЛОЖЬ (значение по умолчанию) – функция возвращает только значения коэффициентов m и b.
- Точность вычислений рассматриваемой функцией зависит от степени близости графика, построенного на основе имеющихся значений, к экспоненциальной кривой.
- В качестве первого или второго аргументов могут быть введены константы массивов, при этом необходимо соблюдать требования к размерностям.
- Если аргумент известные_значения_y указан в виде ссылки на диапазон ячеек, формирующих строку или столбец, каждая строка или столбец соответственно будут интерпретированы как отдельная переменная.
- Если данная функция используется для расчетов с указанием только одной переменной x, первый и второй аргументы могут быть указаны в виде ссылок на диапазоны любой формы. Если по условию имеются две и более переменных x, первый и второй аргументы должны быть указаны в виде векторов данных. Размеры массивов должны совпадать в любом случае.
- Если требуется определить будущие значения переменных (предсказать), можно использовать функцию РОСТ.
АППРОКСИМАЦИЯ ЗАВИСИМОСТЕЙ В EXCEL
Решить задачу аппроксимации экспериментальных данных – значит построить уравнение регрессии. Задача аппроксимации возникает в случае необходимости аналитически, то есть в виде математической зависимости, описать реальные явления, наблюдения за которыми заданы в виде таблицы, содержащей значения показателя в разные моменты времени или при разных значениях независимого аргумента. Например,
— известны показатели прибыли (их можно обозначить Y) в зависимости от размера капиталовложений (X);
— известны объемы реализации фирмы (Y) за шесть недель ее работы. В этом случае, X – это последовательность недель.
Иногда говорят, что требуется построить эмпирическую модель. Эмпирической называется модель, построенная на основе реальных наблюдений. Если модель удается найти, можно сделать прогноз о поведении исследуемого явления и процесса в будущем и, возможно, выбрать оптимальное направление ее развития.
В общем случае задача аппроксимации экспериментальных данных имеет следующую постановку:
Пусть известны данные, полученные практическим путем (в ходе n экспериментов или наблюдений), которые можно представить парами чисел (хi; уi). Зависимость между ними отражает таблица:
| X | х1 | х2 | х3 | … | хn |
| Y | y1 | y2 | y3 | … | yn |
Имеется класс разнообразных функций F. Требуется найти аналитическое (т.е. математическое) выражение зависимости между этими показателями, то есть надо подобрать из множества функций F функцию f, такую что 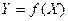 . которая наилучшим образом сглаживала бы экспериментальную зависимость между переменными и по возможности точно отражала общую тенденцию зависимости между X и Y, исключая погрешности измерения и случайные отклонения.
. которая наилучшим образом сглаживала бы экспериментальную зависимость между переменными и по возможности точно отражала общую тенденцию зависимости между X и Y, исключая погрешности измерения и случайные отклонения.
Выяснить вид функции можно либо из теоретических соображений, либо анализируя расположение точек (хi; уi) на координатной плоскости.
Графически решить задачу аппроксимации означает, провести такую кривую  , точки которой (хi; ŷi) находились бы как можно ближе к исходным точкам (хi; уi), отображающим экспериментальные данные.
, точки которой (хi; ŷi) находились бы как можно ближе к исходным точкам (хi; уi), отображающим экспериментальные данные.
Для решения задачи аппроксимации используют метод наименьших квадратов.
При этом функция считается наилучшим приближением к , если для нее сумма квадратов отклонений «теоретических» значений  , найденных по эмпирической формуле, от соответствующих опытных значений
, найденных по эмпирической формуле, от соответствующих опытных значений  , имеет наименьшее значение по сравнению с другими функциями, из числа которых выбирается искомое приближение.
, имеет наименьшее значение по сравнению с другими функциями, из числа которых выбирается искомое приближение.
Математическая запись метода наименьших квадратов имеет вид:
 (1)
(1)
где n — количество наблюдений показателей.
Таким образом, задача аппроксимации распадается на две части.
Сначала устанавливают вид зависимости и, соответственно, вид эмпирической формулы, то есть решают, является ли она линейной, квадратичной, логарифмической или какой-либо другой. Если нет каких-либо теоретических соображений для подбора вида формулы, обычно выбирают функциональную зависимость из числа наиболее простых, сравнивая их графики с графиком заданной функции.
После этого определяются численные значения неизвестных параметров выбранной эмпирической формулы, для которых приближение к заданной функции оказывается наилучшим.
Простейшим видом эмпирической модели с двумя параметрами, используемой для аппроксимации результатов экспериментов, является линейная регрессия, описываемая линейной функцией:

где а, b — искомые параметры.
Для модели линейной регрессии метод наименьших квадратов (1) запишется :
 (2)
(2)
Для решения (2) относительно а и b приравнивают к нулю частные производные:
 В итоге для нахождения a и b надо решить систему линейных алгебраических уравнений вида:
В итоге для нахождения a и b надо решить систему линейных алгебраических уравнений вида:
 (3)
(3)
Реализовать метод наименьших квадратов в случае линейной регрессии в Excel можно различными способами.
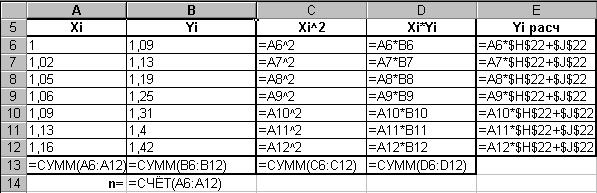
1 способ. Построить систему линейных алгебраических уравнений, подставив в (3) все известные значения, и решить ее, например, матричным методом (см. зад. 4).

В формульном виде элемент расчетной таблицы приведен на рис. 26.
2 способ. Решить в Excel задачу оптимизации (2), применив для этого Поиск решения (см. зад. 5).
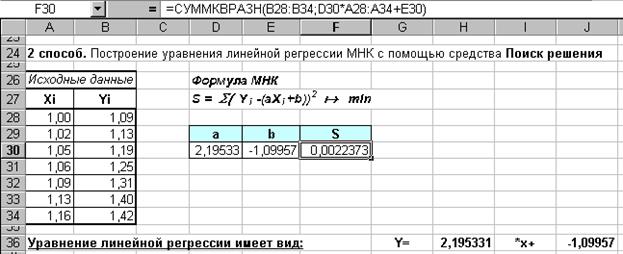
Замечание 1. Следует обратить внимание, что для целевой функции S удобно применить встроенную математическую функцию СУММКВРАЗН(массив1;массив2), в результате которой как раз и вычисляется сумма квадратов разностей двух массивов. В нашем случае следует в качестве массива1 указать диапазон исходных значений , а в качестве массива2 – «теоретические» значения , рассчитанные по формуле  , где a и b – это адреса ячеек с искомыми значениями.
, где a и b – это адреса ячеек с искомыми значениями.
Замечание 2. В диалоговом окне команды Поиск решения следует задать целевую ячейку, направление цели – на минимум и изменяемые ячейки (рис. 28). Данная задача ограничений не содержит.

Замечание3. В качестве эмпирических моделей с двумя параметрами могут использоваться и нелинейные модели вида:

Описанный способ решения метода наименьших квадратов применим и для нелинейных зависимостей.
3 способ. Для нахождения значений параметров a и b в случае линейной регрессии можно использовать следующие встроенные в Excel статистические функции:
ЛИНЕЙН (известные_значения_У; известные_значения_Х)
Причем, функция НАКЛОН ( ) возвращает значение параметра а, функция ОТРЕЗОК( ) возвращает значение параметра b. Функция ЛИНЕЙН( ) возвращает одновременно оба параметра линейной зависимости, так как является функцией массива. Поэтому для ввода функции ЛИНЕЙН( ) в таблицу надо соблюдать следующие правила:
· выделить две рядом стоящие ячейки
· по окончании нажать одновременно комбинацию клавиш Ctrl+ Shift+Enter.
В результате в левой ячейке получится значение параметра а, а в правой – значение параметра b.
Для решения задачи аппроксимации графическим способом в Excel надо построить по исходным данным график, например, точечную диаграмму со значениями, соединенными сглаживающими линиями (см.зад.1). На эту диаграмму Excel может нанести Линию тренда. Линию тренда можно добавить к любому ряду данных, использующему следующие типы диаграмм: диаграммы с областями, графики, гистограммы, линейчатые или точечные диаграммы.
При создании линии тренда в Excel на основе данных диаграммы применяется та или иная аппроксимация. Excel позволяет выбрать один из пяти аппроксимирующих линий или вычислить линию, показывающую скользящее среднее.
Кроме того, Excel предоставляет возможность выбирать значения пересечения линии тренда с осью Y, а также добавлять к диаграмме уравнение аппроксимации и величину достоверности аппроксимации (R 2 ). Также, можно определять будущие и прошлые значения данных, исходя из линии тренда и связанного с ней уравнения аппроксимации.
Чтобы добавить линию тренда к ряду данных надо:
1. Активизировать щелчком мыши диаграмму.
2. Выполнить команду Диаграмма, Добавить линию тренда или переместить указатель на ряд данных, щелкнуть правой кнопкой мыши, а затем в контекстном меню выбрать команду Добавить линию тренда. В появившемся окне Линия тренда раскрыть вкладку Тип (рис. 29)
3. В списке Построен на ряде – выделить ряд данных, к которому нужно добавить линию тренда (Рис.29).
4. В группе Построение линии тренда (аппроксимация и сглаживание) выбрать один из шести типов аппроксимации (сглаживания). – линейная, логарифмическая, полиномиальная, степенная, экспоненциальная, скользящее среднее (Рис.29)

5. Чтобы установить параметры линии тренда надо раскрыть вкладку Параметры диалогового окна Линия тренда(рис. 30)

Показывать уравнение на диаграмме – осуществляет вывод уравнения аппроксимации на диаграмму в виде текстового поля.
Поместить на диаграмму величину достоверности аппроксимации R 2 – осуществляет вывод на диаграмму достоверности аппроксимации в виде текста.
6. По окончании нажимают экранную кнопку ОК.
Пример результирующей диаграммы приведен на рисунке 31.
Урок 4. Виды аппроксимации в Excel
Текст урока с работающими фрагментами расчетов в файле uroki-approksimacii.xls
Как и предыдущие, этот урок с аналогичным текстом лучше смотреть не листе Excel (см. Уроки аппроксимации.xls, Лист1)
Аппроксимация в Excel проще всего реализуется с помощью программы построения трендов. Для выяснения особенностей аппроксимации возьмем какой-либо конкретный пример. Например, энтальпию насыщенного пара по книге С.Л.Ривкина и А.А.Александрова «Теплофизические свойства воды и водяного пара», М., «Энергия», 1980г. В колонке P поместим значения давления в кгс/см2, в колонке i» — энтальпию пара на линии насыщения в ккал/кг и построим график с помощью опции или кнопки «Мастер диаграмм».


Щелкнем правой кнопкой по линии на рисунке, затем левой кнопкой по опции «Добавить линию тренда» и смотрим — какие услуги предлагаются нам этой опцией в части реализации аппроксимации в Excel.
Нам предлагается на выбор пять типов аппроксимации: линейная, степенная, логарифмическая, экспоненциальная и полиноминальная. Чем они хороши и чем могут нам помочь? — Нажимаем кнопку F1, затем щелкаем по опции «Мастер ответов» и в появившееся окошко вводим нужное нам слово «аппроксимация», после чего щелкаем по кнопке «Найти». Выбираем в появившемся списке раздел «Формулы для построения линий тренда».
Получаем следующую информацию в несколько измененной нами
Используется для аппроксимации данных по методу наименьших квадратов в соответствии с уравнением:
где b — угол наклона и a — координата пересечения оси абсцисс (свободный член).
Используется для аппроксимации данных по методу наименьших квадратов в соответствии с уравнением:
где c и b — константы.
Используется для аппроксимации данных по методу наименьших квадратов в соответствии с уравнением:
где a и b — константы.
Используется для аппроксимации данных по методу наименьших квадратов в соответствии с уравнением:
где b и k — константы.
Используется для аппроксимации данных по методу наименьших квадратов в соответствии с уравнением:
где a, b1, b2, b3. b6 — константы.
Снова щелкаем по линии рисунка, затем по опции «Добавить линию тренда», далее по опции «Параметры» и ставим флажки в окошках слева от записей: «показывать уравнение на диаграмме» и «поместить на диаг- рамму величину достоверности аппроксимации R^2, после чего щелкаем по кнопке OK. Пробуем все варианты аппроксимации по порядку.
Линейная аппроксимация дает нам R^2=0.9291 — это низкая достоверность и плохой результат.
Для перехода к степенной аппроксимации щелкаем правой кнопкой по линии тренда, затем левой кнопкой — по опции «Формат линии тренда», далее по опциям «Тип» и «Степенная». На этот раз получили R^2=0.999.
Запишем уравнение линии тренда в виде, пригодном для расчетов на листе Excel:
В результате имеем:

Максимальная погрешность аппроксимации получилась на уровне 0.23 ккал/кг. Для аппроксимации экспериментальных данных такой результат был бы чудесным, но для аппроксимации справочной таблицы это не слишком хороший результат. Поэтому попробуем проверить другие варианты аппроксимации в Excel посредством программы построения трендов.
Логарифмическая аппроксимация дает нам R^2=0.9907 — несколько хуже, чем по степенному варианту. Экспоненнта в том варианте, который предлагает программа построения трендов, вообще не подошла — R^2=0.927.
Полиноминальная аппроксимация со степенью 2 (это y=a+b1*x+b2*x^2) обеспечила R^2=0.9896. При степени 3 получили R^2=0.999, но с явным искажением аппроксимируемой кривой, в особенности при P>0.07 кгс/см2. Наконец, пятая степень нам дает R^2=1 — это, как утверждается, максимально тесная связь между исходными данными и их аппроксимацией.
Перепишем уравнение полинома в пригодном для расчетов на листе Excel виде:
и сравним результат аппроксимации с исходной таблицей:

Оказалось, что R^2=1 в данном случае лишь блестящая ложь. Реально, самый лучший результат полиноминальной аппроксимации дал самый простой полином вида y=a+b1*x+b2*x^2. Но его результат хуже, чем в варианте степенной аппроксимации y=634.16*x^0.012, где максимальная погрешность аппроксимации находилась на уровне 0.23 ккал/кг. Это все, что мы можем выжать из программы построения трендов. Посмотрим, что мы можем выжать из функции Линейн. Для нее попробуем вариант степенной аппроксимации.
Примечание. Обнаруженный дефект связан с работой программы построения трендов, но не с методом МНК.
Аппроксимация в Excel
 (Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
(Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
Учет и контроль! Те, кому за 40 должны хорошо помнить этот лозунг из эпохи построения социализма и коммунизма в нашей стране.
Но без хорошо налаженного учета невозможно эффективное функционирование ни страны, ни области, ни предприятия, ни домашнего хозяйства при любой общественно-экономической формации общества! Для составления прогнозов и планов деятельности и развития необходимы исходные данные. Где их брать? Только один достоверный источник – это ваши статистические учетные данные предыдущих периодов времени.
Учитывать результаты своей деятельности, собирать и записывать информацию, обрабатывать и анализировать данные, применять результаты анализа для принятия правильных решений в будущем должен, в моем понимании, каждый здравомыслящий человек. Это есть ничто иное, как накопление и рациональное использование своего жизненного опыта. Если не вести учет важных данных, то вы через определенный период времени их забудете и, начав заниматься этими вопросами вновь, вы опять наделаете те же ошибки, что делали, когда впервые этим занимались.
«Мы, помню, 5 лет назад изготавливали до 1000 штук таких изделий в месяц, а сейчас и 700 еле-еле собираем!». Открываем статистику и видим, что 5 лет назад и 500 штук не изготавливали…
«Во сколько обходится километр пробега твоего автомобиля с учетом всех затрат?» Открываем статистику – 6 руб./км. Поездка на работу – 107 рублей. Дешевле, чем на такси (180 рублей) более чем в полтора раза. А бывали времена, когда на такси было дешевле…
«Сколько времени требуется для изготовления металлоконструкций уголковой башни связи высотой 50 м?» Открываем статистику – и через 5 минут готов ответ…
«Сколько будет стоить ремонт комнаты в квартире?» Поднимаем старые записи, делаем поправку на инфляцию за прошедшие годы, учитываем, что в прошлый раз купили материалы на 10% дешевле рыночной цены и – ориентировочную стоимость мы уже знаем…
Ведя учет своей профессиональной деятельности, вы всегда будете готовы ответить на вопрос начальника: «Когда. ». Ведя учет домашнего хозяйства, легче спланировать расходы на крупные покупки, отдых и прочие расходы в будущем, приняв соответствующие меры по дополнительному заработку или по сокращению необязательных расходов сегодня.
В этой статье я на простом примере покажу, как можно обрабатывать собранные статистические данные в Excel для возможности дальнейшего использования при прогнозировании будущих периодов.
Аппроксимация в Excel статистических данных аналитической функцией.
Производственный участок изготавливает строительные металлоконструкции из листового и профильного металлопроката. Участок работает стабильно, заказы однотипные, численность рабочих колеблется незначительно. Есть данные о выпуске продукции за предыдущие 12 месяцев и о количестве переработанного в эти периоды времени металлопроката по группам: листы, двутавры, швеллеры, уголки, трубы круглые, профили прямоугольного сечения, круглый прокат. После предварительного анализа исходных данных возникло предположение, что суммарный месячный выпуск металлоконструкций существенно зависит от количества уголков в заказах. Проверим это предположение.
Прежде всего, несколько слов об аппроксимации. Мы будем искать закон – аналитическую функцию, то есть функцию, заданную уравнением, которое лучше других описывает зависимость общего выпуска металлоконструкций от количества уголкового проката в выполненных заказах. Это и есть аппроксимация, а найденное уравнение называется аппроксимирующей функцией для исходной функции, заданной в виде таблицы.
1. Включаем Excel и помещаем на лист таблицу с данными статистики.
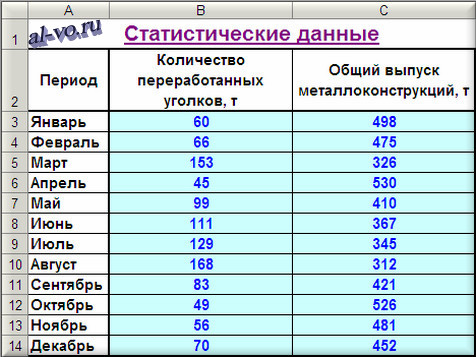
2. Далее строим и форматируем точечную диаграмму, в которой по оси X задаем значения аргумента – количество переработанных уголков в тоннах. По оси Y откладываем значения исходной функции – общий выпуск металлоконструкций в месяц, заданные таблицей.
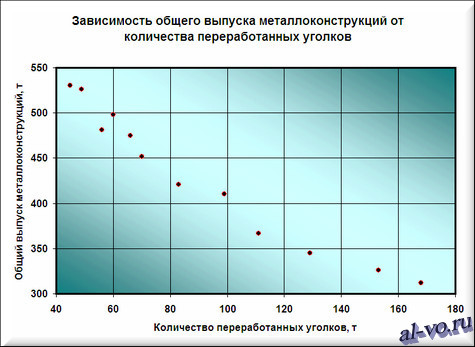
О том, как построить подобную диаграмму, подробно рассказано в статье «Как строить графики в Excel?».
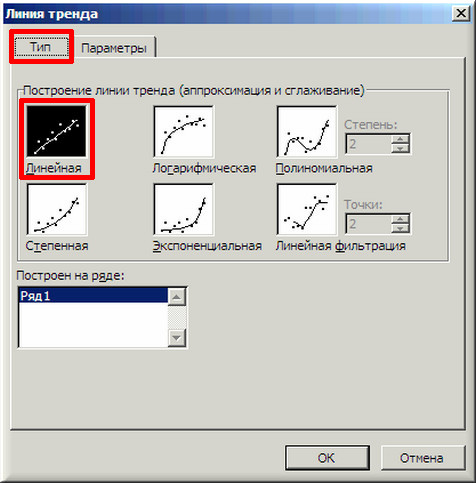
3. «Наводим» мышь на любую из точек на графике и щелчком правой кнопки вызываем контекстное меню (как говорит один мой хороший товарищ — работая в незнакомой программе, когда не знаешь, что делать, чаще щелкай правой кнопкой мыши…). В выпавшем меню выбираем «Добавить линию тренда…».
4. В появившемся окне «Линия тренда» на вкладке «Тип» выбираем «Линейная».
5. Далее на вкладке «Параметры» ставим 2 галочки и нажимаем «ОК».
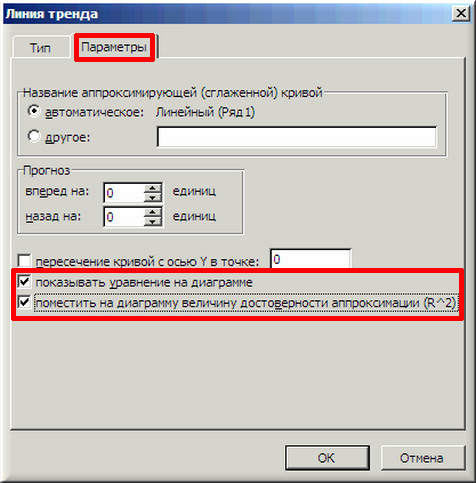
6. На графике появилась прямая линия, аппроксимирующая нашу табличную зависимость.
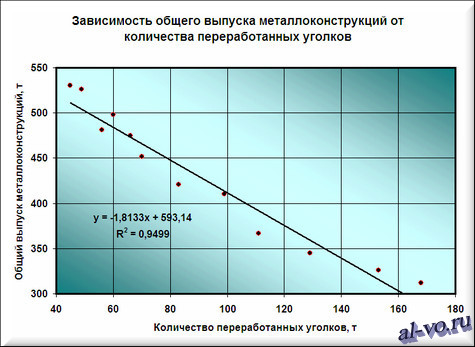
Мы видим кроме самой линии уравнение этой линии и, главное, мы видим значение параметра R 2 – величины достоверности аппроксимации! Чем ближе его значение к 1, тем наиболее точно выбранная функция аппроксимирует табличные данные!
7. Строим линии тренда, используя степенную, логарифмическую, экспоненциальную и полиномиальную аппроксимации по аналогии с тем, как мы строили линейную линию тренда.
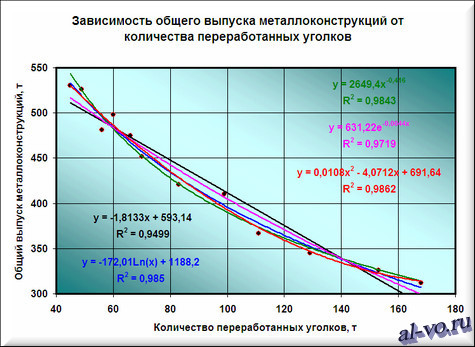
Лучше всех из выбранных функций аппроксимирует наши данные полином второй степени, у него максимальный коэффициент достоверности R 2 .
Однако хочу вас предостеречь! Если вы возьмете полиномы более высоких степеней, то, возможно, получите еще лучшие результаты, но кривые будут иметь замысловатый вид…. Здесь важно понимать, что мы ищем функцию, которая имеет физический смысл. Что это означает? Это означает, что нам нужна аппроксимирующая функция, которая будет выдавать адекватные результаты не только внутри рассматриваемого диапазона значений X, но и за его пределами, то есть ответит на вопрос: «Какой будет выпуск металлоконструкций при количестве переработанных за месяц уголков меньше 45 и больше 168 тонн!» Поэтому я не рекомендую увлекаться полиномами высоких степеней, да и параболу (полином второй степени) выбирать осторожно!
Итак, нам необходимо выбрать функцию, которая не только хорошо интерполирует табличные данные в пределах диапазона значений X=45…168, но и допускает адекватную экстраполяцию за пределами этого диапазона. Я выбираю в данном случае логарифмическую функцию, хотя можно выбрать и линейную, как наиболее простую. В рассматриваемом примере при выборе линейной аппроксимации в excel ошибки будут больше, чем при выборе логарифмической, но не на много.
8. Удаляем все линии тренда с поля диаграммы, кроме логарифмической функции. Для этого щелкаем правой кнопкой мыши по ненужным линиям и в выпавшем контекстном меню выбираем «Очистить».
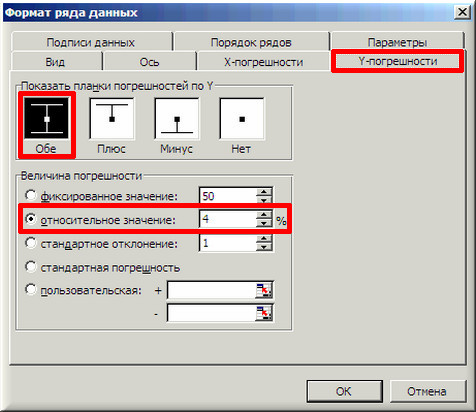
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.
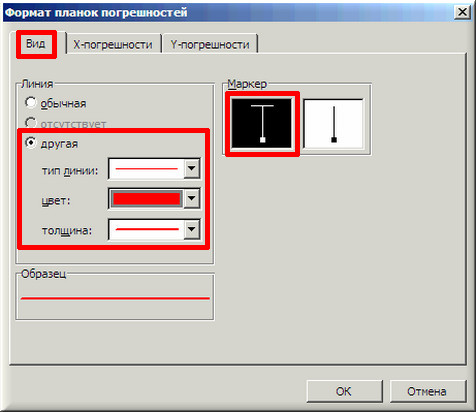
10. Затем щелкаем по любой из линий диапазонов погрешностей правой кнопкой мыши, выбираем в контекстном меню «Формат полос погрешностей…» и в окне «Формат планок погрешностей» на вкладке «Вид» настраиваем цвет и толщину линий.
Аналогичным образом форматируются любые другие объекты диаграммы в Excel!
Окончательный результат диаграммы представлен на следующем снимке экрана.
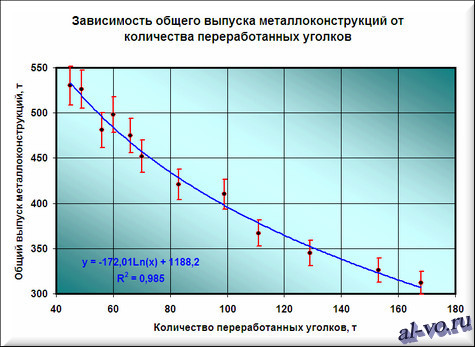
Итоги.
Результатом всех предыдущих действий стала полученная формула аппроксимирующей функции y=-172,01*ln (x)+1188,2. Зная ее, и количество уголков в месячном наборе работ, можно с высокой степенью вероятности (±4% — смотри планки погрешностей) спрогнозировать общий выпуск металлоконструкций за месяц! Например, если в плане на месяц 140 тонн уголков, то общий выпуск, скорее всего, при прочих равных составит 338±14 тонн.
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R 2 >0,87. Отличный результат – при R 2 >0,94.
На практике бывает трудно выделить один самый главный определяющий фактор (в нашем примере – масса переработанных за месяц уголков), но если постараться, то в каждой конкретной задаче его всегда можно найти! Конечно, общий выпуск продукции за месяц реально зависит от сотни факторов, для учета которых необходимы существенные трудозатраты нормировщиков и других специалистов. Только результат все равно будет приблизительным! Так стоит ли нести затраты, если есть гораздо более дешевое математическое моделирование!
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых переменных…. Об этом и не только читайте в следующих статьях на блоге.
Подписывайтесь на анонсы статей в окне, расположенном в конце каждой статьи или в окне вверху страницы.
Не забывайте подтверждать подписку кликом по ссылке в письме, которое придет к вам на указанную почту (может прийти в папку «Спам»).
С интересом прочту Ваши комментарии, уважаемые читатели! Пишите!
P.S. (04.06.2017)
Высокоточная красивая замена табличных данных простым уравнением.
Вас не устраивают полученные точность аппроксимации (R 2 2 =0,9963.